Why veilSense
The benefits that actually matter.
Built for teams that need AI to work on their terms — private, reliable, and fully in their control.
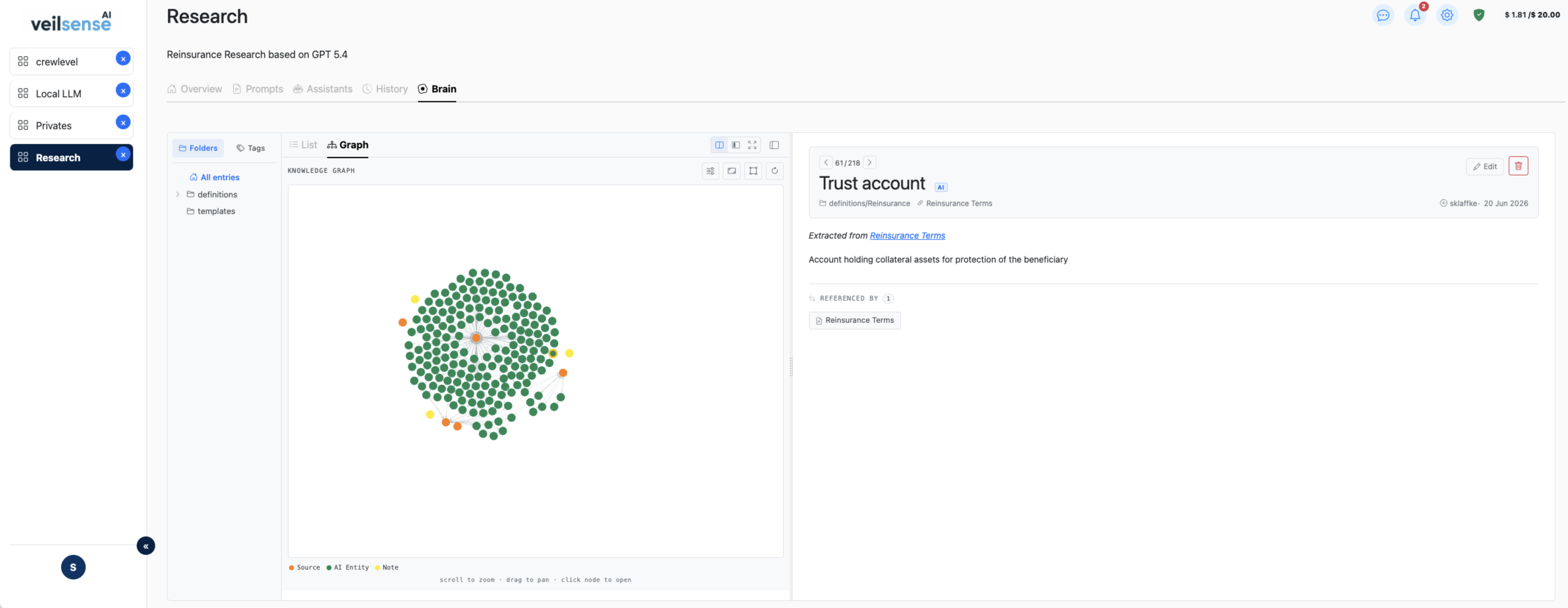
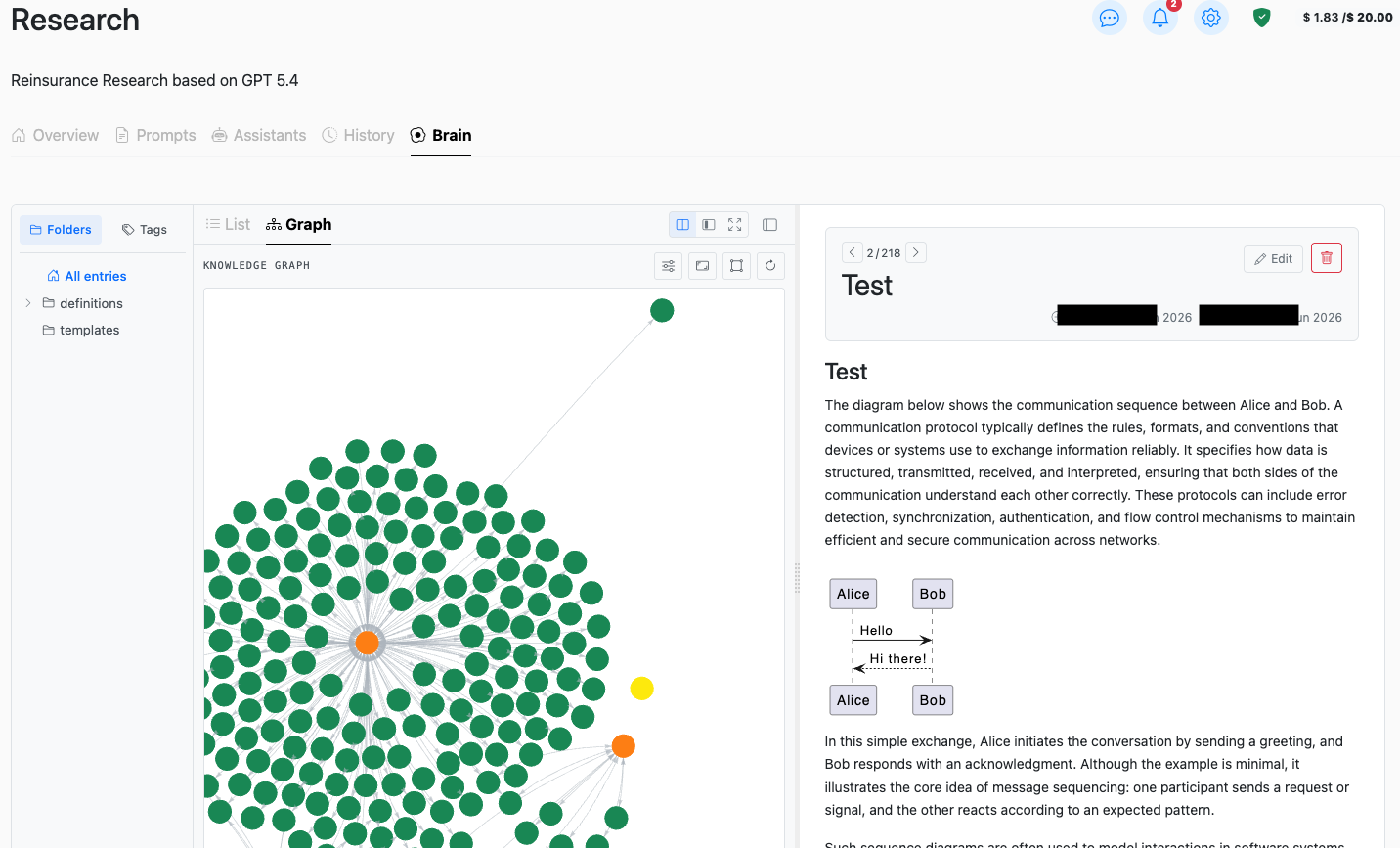
One place for everything your team knows
Collect chat responses, uploaded documents, research, meeting notes, and work results into a single searchable Brain. One source of truth — always up to date.
AI that answers from your data, not guesses
Assistants search your indexed Brain before responding. No hallucinations — every answer is grounded in content you control, not a language model's approximation.
Your LLM, your choice — including local models
Connect OpenAI, Claude, Gemini, or a local Ollama instance. Switch models per workspace without rebuilding anything. No vendor lock-in.
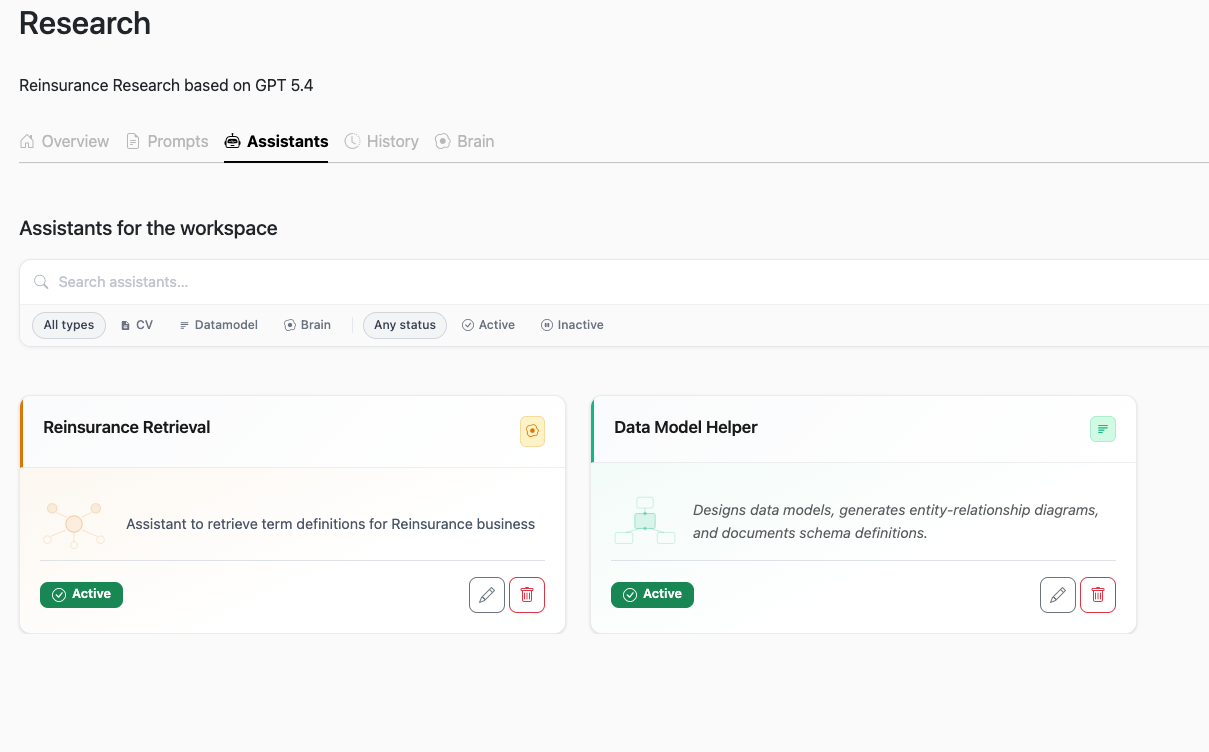
Live in minutes, not months
Pre-built assistants for Q&A, CV matching, and data modelling — ready to run from day one. No custom prompt engineering required to get started.
Open Source — just install with Docker
veilSense is fully open source. No license required — spin it up with a single Docker Compose command. The only costs are your own LLM API tokens and Tavily credits, billed directly by the provider.
Separate knowledge, restrict access
Organize teams, departments, or clients into isolated workspaces. Each workspace sees only what you allow — no cross-contamination, no accidental leaks.
Reuse your best prompts across the team
Build prompt templates once and share them within a workspace. Standardize how your team interacts with AI — consistent output, no duplicated effort.
Keep AI costs visible and under control
Set a monthly LLM budget per workspace. A live indicator shows current spend vs. limit so teams never exceed what you've reserved — no billing surprises.
Reach beyond your Brain when needed
When internal knowledge isn't enough, veilSense can extend search to the web via Tavily. Fresh external results are stored back into Brain automatically — filling gaps without leaving the platform.